
Наглядный пример регуляризации логистической регрессии
В 1 статье уже приводился пример того, как полиномиальные признаки позволяют линейным моделям строить нелинейные разделяющие поверхности. Покажем это в картинках.
Посмотрим, как регуляризация влияет на качество классификации на наборе данных по тестированию микрочипов из курса Andrew Ng по машинному обучению.Будем использовать логистическую регрессию с полиномиальными признаками и варьировать параметр регуляризации C.
Сначала посмотрим, как регуляризация влияет на разделяющую границу классификатора, интуитивно распознаем переобучение и недообучение.Потом численно установим близкий к оптимальному параметр регуляризации с помощью кросс-валидации (cross-validation) и перебора по сетке (GridSearch).
Загружаем данные с помощью метода read_csv библиотеки pandas. В этом наборе данных для 118 микрочипов (объекты) указаны результаты двух тестов по контролю качества (два числовых признака) и сказано, пустили ли микрочип в производство. Признаки уже центрированы, то есть из всех значений вычтены средние по столбцам. Таким образом, «среднему» микрочипу соответствуют нулевые значения результатов тестов.
Посмотрим на первые и последние 5 строк.
Сохраним обучающую выборку и метки целевого класса в отдельных массивах NumPy. Отобразим данные. Красный цвет соответствует бракованным чипам, зеленый – нормальным.
X = data.ix[:,:2].values
y = data.ix[:,2].valuesplt.scatter(X[y == 1, 0], X[y == 1, 1], c='green', label='Выпущен')
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='red', label='Бракован')
plt.xlabel("Тест 1")
plt.ylabel("Тест 2")
plt.title('2 теста микрочипов')
plt.legend();Определяем функцию для отображения разделяющей кривой классификатора
def plot_boundary(clf, X, y, grid_step=.01, poly_featurizer=None):
x_min, x_max = X[:, 0].min() - .1, X[:, 0].max() .1
y_min, y_max = X[:, 1].min() - .1, X[:, 1].max() .1
xx, yy = np.meshgrid(np.arange(x_min, x_max, grid_step),
np.arange(y_min, y_max, grid_step))
# каждой точке в сетке [x_min, m_max]x[y_min, y_max]
# ставим в соответствие свой цвет
Z = clf.predict(poly_featurizer.transform(np.c_[xx.ravel(), yy.ravel()]))
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, cmap=plt.cm.Paired)Полиномиальными признаками до степени 




Попросту говоря, таких признаков экспоненциально много, и строить, скажем, для 100 признаков полиномиальные степени 10 может оказаться затратно (а более того, и не нужно). Создадим объект sklearn, который добавит в матрицу 

Также проверим долю правильных ответов классификатора на обучающей выборке. Видим, что регуляризация оказалась слишком сильной, и модель «недообучилась». Доля правильных ответов классификатора на обучающей выборке оказалась равной 0.627.
poly = PolynomialFeatures(degree=7)
X_poly = poly.fit_transform(X)C = 1e-2
logit = LogisticRegression(C=C, n_jobs=-1, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=.01, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='green', label='Выпущен')
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='red', label='Бракован')
plt.xlabel("Тест 1")
plt.ylabel("Тест 2")
plt.title('2 теста микрочипов. Логит с C=0.01')
plt.legend();
print("Доля правильных ответов классификатора на обучающей выборке:",
round(logit.score(X_poly, y), 3))Увеличим  ослабляем регуляризацию, теперь в решении значения весов логистической регрессии могут оказаться больше (по модулю), чем в прошлом случае. Теперь доля правильных ответов классификатора на обучающей выборке – 0.831.
ослабляем регуляризацию, теперь в решении значения весов логистической регрессии могут оказаться больше (по модулю), чем в прошлом случае. Теперь доля правильных ответов классификатора на обучающей выборке – 0.831.
C = 1
logit = LogisticRegression(C=C, n_jobs=-1, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=.005, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='green', label='Выпущен')
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='red', label='Бракован')
plt.xlabel("Тест 1")
plt.ylabel("Тест 2")
plt.title('2 теста микрочипов. Логит с C=1')
plt.legend();
print("Доля правильных ответов классификатора на обучающей выборке:",
round(logit.score(X_poly, y), 3))Еще увеличим
Доля правильных ответов классификатора на обучающей выборке – 0.873.
C = 1e4
logit = LogisticRegression(C=C, n_jobs=-1, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=.005, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c='green', label='Выпущен')
plt.scatter(X[y == 0, 0], X[y == 0, 1], c='red', label='Бракован')
plt.xlabel("Тест 1")
plt.ylabel("Тест 2")
plt.title('2 теста микрочипов. Логит с C=10k')
plt.legend();
print("Доля правильных ответов классификатора на обучающей выборке:",
round(logit.score(X_poly, y), 3))Чтоб обсудить результаты, перепишем формулу для функционала, который оптимизируется в логистической регрессии, в таком виде:
где
Промежуточные выводы:
- чем больше параметр , тем более сложные зависимости в данных может восстанавливать модель (интуитивно соответствует «сложности» модели (model capacity))
- если регуляризация слишком сильная (малые значения ), то решением задачи минимизации логистической функции потерь может оказаться то, когда многие веса занулились или стали слишком малыми. Еще говорят, что модель недостаточно «штрафуется» за ошибки (то есть в функционале
 «перевешивает» сумма квадратов весов, а ошибка
«перевешивает» сумма квадратов весов, а ошибка  может быть относительно большой). В таком случае модель окажется недообученной (1 случай)
может быть относительно большой). В таком случае модель окажется недообученной (1 случай) - наоборот, если регуляризация слишком слабая (большие значения ), то решением задачи оптимизации может стать вектор
 с большими по модулю компонентами. В таком случае больший вклад в оптимизируемый функционал имеет и, вольно выражаясь, модель слишком «боится» ошибиться на объектах обучающей выборки, поэтому окажется переобученной (3 случай)
с большими по модулю компонентами. В таком случае больший вклад в оптимизируемый функционал имеет и, вольно выражаясь, модель слишком «боится» ошибиться на объектах обучающей выборки, поэтому окажется переобученной (3 случай) - то, какое значение выбрать, сама логистическая регрессия «не поймет» (или еще говорят «не выучит»), то есть это не может быть определено решением оптимизационной задачи, которой является логистическая регрессия (в отличие от весов ). Так же точно, дерево решений не может «само понять», какое ограничение на глубину выбрать (за один процесс обучения). Поэтому – это гиперпараметр модели, который настраивается на кросс-валидации, как и max_depth для дерева.
Настройка параметра регуляризации
Теперь найдем оптимальное (в данном примере) значение параметра регуляризации
Выделим участок с «лучшими» значениями C.
Как мы помним, такие кривые называются валидационными, раньше мы их строили вручную, но в sklearn для них их построения есть специальные методы, которые мы тоже сейчас будем использовать.
Кривые валидации и обучения
Мы уже получили представление о проверке модели, кросс-валидации и регуляризации.Теперь рассмотрим главный вопрос:
Если качество модели нас не устраивает, что делать?
Ответы на данные вопросы не всегда лежат на поверхности. В частности, иногда использование более сложной модели приведет к ухудшению показателей. Либо добавление наблюдений не приведет к ощутимым изменениям. Способность принять правильное решение и выбрать правильный способ улучшения модели, собственно говоря, и отличает хорошего специалиста от плохого.
Будем работать со знакомыми данными по оттоку клиентов телеком-оператора.
Логистическую регрессию будем обучать стохастическим градиентным спуском. Пока объясним это тем, что так быстрее, но далее в программе у нас отдельная статья про это дело. Построим валидационные кривые, показывающие, как качество (ROC AUC) на обучающей и проверочной выборке меняется с изменением параметра регуляризации.
alphas = np.logspace(-2, 0, 20)
sgd_logit = SGDClassifier(loss='log', n_jobs=-1, random_state=17)
logit_pipe = Pipeline([('scaler', StandardScaler()), ('poly', PolynomialFeatures(degree=2)),
('sgd_logit', sgd_logit)])
val_train, val_test = validation_curve(logit_pipe, X, y,
'sgd_logit__alpha', alphas, cv=5,
scoring='roc_auc')
def plot_with_err(x, data, **kwargs):
mu, std = data.mean(1), data.std(1)
lines = plt.plot(x, mu, '-', **kwargs)
plt.fill_between(x, mu - std, mu std, edgecolor='none',
facecolor=lines[0].get_color(), alpha=0.2)
plot_with_err(alphas, val_train, label='training scores')
plot_with_err(alphas, val_test, label='validation scores')
plt.xlabel(r'$alpha$'); plt.ylabel('ROC AUC')
plt.legend();Тенденция видна сразу, и она очень часто встречается.
Сколько нужно данных?
Известно, что чем больше данных использует модель, тем лучше. Но как нам понять в конкретной ситуации, помогут ли новые данные? Скажем, целесообразно ли нам потратить N$ на труд асессоров, чтобы увеличить выборку вдвое?
Поскольку новых данных пока может и не быть, разумно поварьировать размер имеющейся обучающей выборки и посмотреть, как качество решения задачи зависит от объема данных, на котором мы обучали модель. Так получаются кривые обучения (learning curves).
Идея простая: мы отображаем ошибку как функцию от количества примеров, используемых для обучения. При этом параметры модели фиксируются заранее.
Давайте посмотрим, что мы получим для линейной модели. Коэффициент регуляризации выставим большим.
from sklearn.model_selection import learning_curve
def plot_learning_curve(degree=2, alpha=0.01):
train_sizes = np.linspace(0.05, 1, 20)
logit_pipe = Pipeline([('scaler', StandardScaler()), ('poly', PolynomialFeatures(degree=degree)),
('sgd_logit', SGDClassifier(n_jobs=-1, random_state=17, alpha=alpha))])
N_train, val_train, val_test = learning_curve(logit_pipe,
X, y, train_sizes=train_sizes, cv=5,
scoring='roc_auc')
plot_with_err(N_train, val_train, label='training scores')
plot_with_err(N_train, val_test, label='validation scores')
plt.xlabel('Training Set Size'); plt.ylabel('AUC')
plt.legend()
plot_learning_curve(degree=2, alpha=10)Типичная ситуация: для небольшого объема данных ошибки на обучающей выборке и в процессе кросс-валидации довольно сильно отличаются, что указывает на переобучение. Для той же модели, но с большим объемом данных ошибки «сходятся», что указывается на недообучение.
Если добавить еще данные, ошибка на обучающей выборке не будет расти, но с другой стороны, ошибка на тестовых данных не будет уменьшаться.
Получается, ошибки «сошлись», и добавление новых данных не поможет. Собственно, это случай – самый интересный для бизнеса. Возможна ситуация, когда мы увеличиваем выборку в 10 раз. Но если не менять сложность модели, это может и не помочь. То есть стратегия «настроил один раз – дальше использую 10 раз» может и не работать.
Что будет, если изменить коэффициент регуляризации (уменьшить до 0.05)?
Видим хорошую тенденцию – кривые постепенно сходятся, и если дальше двигаться направо (добавлять в модель данные), можно еще повысить качество на валидации.
А если усложнить модель ещё больше (
Проявляется переобучение – AUC падает как на обучении, так и на валидации.
Строя подобные кривые, можно понять, в какую сторону двигаться, и как правильно настроить сложность модели на новых данных.
Выводы по кривым валидации и обучения
- Ошибка на обучающей выборке сама по себе ничего не говорит о качестве модели
- Кросс-валидационная ошибка показывает, насколько хорошо модель подстраивается под данные (имеющийся тренд в данных), сохраняя при этом способность обобщения на новые данные
- Валидационная кривая представляет собой график, показывающий результат на тренировочной и валидационной выборке в зависимости от сложности модели:
- если две кривые распологаются близко, и обе ошибки велики, — это признак недообучения
- если две кривые далеко друг от друга, — это показатель переобучения
- Кривая обучения — это график, показывающий результаты на валидации и тренировочной подвыборке в зависимости от количества наблюдений:
- если кривые сошлись друг к другу, добавление новых данных не поможет – надо менять сложность модели
- если кривые еще не сошлись, добавление новых данных может улучшить результат.
Метод максимального правдоподобия
У читателя вполне резонно могли возникнуть вопросы: например, почему мы минимизируем среднеквадратичную ошибку, а не что-то другое. Ведь можно минимизировать среднее абсолютное значение невязки или еще что-то. Единственное, что произойдёт в случае изменения минимизируемого значения, так это то, что мы выйдем из условий теоремы Маркова-Гаусса, и наши оценки перестанут быть лучшими среди линейных и несмещенных.
Давайте перед тем как продолжить, сделаем лирическое отступление, чтобы проиллюстрировать метод максимального правдоподобия на простом примере.
Как-то после школы я заметил, что все помнят формулу этилового спирта. Тогда я решил провести эксперимент: помнят ли люди более простую формулу метилового спирта: 
 распределения Бернулли: случайная величина
распределения Бернулли: случайная величина 



 независимых экспериментов, обозначим их исходы как
независимых экспериментов, обозначим их исходы как  правдоподобие наших данных (наблюдений), то есть вероятность наблюдать 117 реализаций случайной величины
правдоподобие наших данных (наблюдений), то есть вероятность наблюдать 117 реализаций случайной величины 


Получается, что наша интуитивная оценка – это и есть оценка максимального правдоподобия. Применим теперь те же рассуждения для задачи линейной регрессии и попробуем выяснить, что лежит за среднеквадратичной ошибкой. Для этого нам придется посмотреть на линейную регрессию с вероятностной точки зрения. Модель, естественно, остается такой же:
но будем теперь считать, что случайные ошибки берутся из центрированного нормального распределения:
Перепишем модель в новом свете:
Так как примеры берутся независимо (ошибки не скоррелированы – одно из условий теоремы Маркова-Гаусса), то полное правдоподобие данных будет выглядеть как произведение функций плотности 

Таким образом, мы увидели, что максимизация правдоподобия данных – это то же самое, что и минимизация среднеквадратичной ошибки (при справедливости указанных выше предположений). Получается, что именно такая функция стоимости является следствием того, что ошибка распределена нормально, а не как-то по-другому.
Принцип максимального правдоподобия и логистическая регрессия
Теперь посмотрим, как из принципа максимального правдоподобия получается оптимизационная задача, которую решает логистическая регрессия, а именно, – минимизация логистической функции потерь.Только что мы увидели, что логистическая регрессия моделирует вероятность отнесения примера к классу » » как
Тогда для класса «-» аналогичная вероятность:
Оба этих выражения можно ловко объединить в одно (следите за моими руками – не обманывают ли вас):
Выражение  отступом (margin) классификации на объекте
отступом (margin) классификации на объекте 
Заметим, что отступ определен для объектов именно обучающей выборки, для которых известны реальные метки целевого класса 
Чтобы понять, почему это мы сделали такие выводы, обратимся к геометрической интерпретации линейного классификатора. Подробно про это можно почитать в материалах Евгения Соколова.
Рекомендую решить почти классическую задачу из начального курса линейной алгебры: найти расстояние от точки с радиус-вектором 


- если отступ большой (по модулю) и положительный, это значит, что метка класса поставлена правильно, а объект находится далеко от разделяющей гиперплоскости (такой объект классифицируется уверенно). На рисунке –
 .
. - если отступ большой (по модулю) и отрицательный, значит метка класса поставлена неправильно, а объект находится далеко от разделяющей гиперплоскости (скорее всего такой объект – аномалия, например, его метка в обучающей выборке поставлена неправильно). На рисунке – .
- если отступ малый (по модулю), то объект находится близко к разделяющей гиперплоскости, а знак отступа определяет, правильно ли объект классифицирован. На рисунке – и
 .
.
Теперь распишем правдоподобие выборки, а именно, вероятность наблюдать данный вектор  i.i.d.). Тогдагде
i.i.d.). Тогдагде 
Как водится, возьмем логарифм данного выражения (сумму оптимизировать намного проще, чем произведение):
То есть в даном случае принцип максимизации правдоподобия приводит к минимизации выражения
Это логистическая функция потерь, просуммированная по всем объектам обучающей выборки.
Посмотрим на новую фунцию как на функцию от отступа:  zero-one loss), которая просто штрафует модель на 1 за ошибку на каждом объекте (отступ отрицательный):
zero-one loss), которая просто штрафует модель на 1 за ошибку на каждом объекте (отступ отрицательный): ![$L_{1/0}(M) = [M < 0]$](https://habrastorage.org/getpro/habr/formulas/279/e2d/d4f/279e2dd4f16fba5aaba3bb74abc2ca6a.svg)
Картинка отражает общую идею, что в задаче классификации, не умея напрямую минимизировать число ошибок (по крайней мере, градиентными методами это не сделать – производная 1/0 функциий потерь в нуле обращается в бесконечность), мы минимизируем некоторую ее верхнюю оценку. В данном случае это логистическая функция потерь (где логарифм двоичный, но это не принципиально), и справедливо
где 



Уравнение множественной регрессии онлайн
Назначение сервиса. С помощью онлайн-калькулятора можно найти следующие показатели:
- уравнение множественной регрессии, матрица парных коэффициентов корреляции, средние коэффициенты эластичности для линейной регрессии;
- множественный коэффициент детерминации, доверительные интервалы для индивидуального и среднего значения результативного признака;
Кроме этого проводится проверка на автокорреляцию остатков и гетероскедастичность.
При вычислении параметров уравнения множественной регрессии используется матричный метод. Для множественной регрессии с двумя переменными (m = 2), можно воспользоваться методом решения системы уравнений.
Построение уравнения множественной регрессии начинается с решения вопроса о спецификации модели, который в свою очередь включает 2 круга вопросов: отбор факторов и выбор уравнения регрессии.
Отбор факторов обычно осуществляется в два этапа:
- теоретический анализ взаимосвязи результата и круга факторов, которые оказывают на него существенное влияние;
- количественная оценка взаимосвязи факторов с результатом. При линейной форме связи между признаками данный этап сводится к анализу корреляционной матрицы (матрицы парных линейных коэффициентов корреляции). Научно обоснованное решение задач подобного вида также осуществляется с помощью дисперсионного анализа — однофакторного, если проверяется существенность влияния того или иного фактора на рассматриваемый признак, или многофакторного в случае изучения влияния на него комбинации факторов.
Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям:
- Они должны быть количественно измеримы. Если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность.
- Каждый фактор должен быть достаточно тесно связан с результатом (т.е. коэффициент парной линейной корреляции между фактором и результатом должен быть существенным).
- Факторы не должны быть сильно коррелированы друг с другом, тем более находиться в строгой функциональной связи (т.е. они не должны быть интеркоррелированы). Разновидностью интеркоррелированности факторов является мультиколлинеарность — тесная линейная связь между факторами.
Пример. Постройте регрессионную модель с 2-мя объясняющими переменными (множественная регрессия). Определите теоретическое уравнение множественной регрессии. Оцените адекватность построенной модели.
Решение.
К исходной матрице X добавим единичный столбец, получив новую матрицу X
| 1 | 5 | 14.5 |
| 1 | 12 | 18 |
| 1 | 6 | 12 |
| 1 | 7 | 13 |
| 1 | 8 | 14 |
Матрица Y
Транспонируем матрицу X, получаем XT:
| 1 | 1 | 1 | 1 | 1 |
| 5 | 12 | 6 | 7 | 8 |
| 14.5 | 18 | 12 | 13 | 14 |
В матрице, (XTX) число 5, лежащее на пересечении 1-й строки и 1-го столбца, получено как сумма произведений элементов 1-й строки матрицы XT и 1-го столбца матрицы X
Находим обратную матрицу (XTX)-1
| 13.99 | 0.64 | -1.3 |
| 0.64 | 0.1 | -0.0988 |
| -1.3 | -0.0988 | 0.14 |
Вектор оценок коэффициентов регрессии равен
(XTX)-1XTY = y(x) = |
| * | = |
Получили оценку уравнения регрессии: Y = 34.66 1.97X1-2.45X2
Оценка значимости уравнения множественной регрессии осуществляется путем проверки гипотезы о равенстве нулю коэффициент детерминации рассчитанного по данным генеральной совокупности. Для ее проверки используют F-критерий Фишера.
R2 = 1 - s2e/∑(yi - yср)2 = 1 - 33.18/77.2 = 0.57F = R2/(1 - R2)*(n - m -1)/m = 0.57/(1 - 0.57)*(5-2-1)/2 = 1.33
Табличное значение при степенях свободы k1 = 2 и k2 = n-m-1 = 5 - 2 -1 = 2, Fkp(2;2) = 19
Поскольку фактическое значение F = 1.33 < Fkp, то коэффициент детерминации статистически не значим, а следовательно, полученное уравнение регрессии статистически ненадежно. Это означает, что его нельзя использовать для прогноза и дальнейшего анализа.
Пример №2. Приведены данные за 15 лет по темпам прироста заработной платы Y (%), производительности труда X1 (%), а также по уровню инфляции X2 (%).
| Год | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X1 | 3,5 | 2,8 | 6,3 | 4,5 | 3,1 | 1,5 | 7,6 | 6,7 | 4,2 | 2,7 | 4,5 | 3,5 | 5,0 | 2,3 | 2,8 |
| X2 | 4,5 | 3,0 | 3,1 | 3,8 | 3,8 | 1,1 | 2,3 | 3,6 | 7,5 | 8,0 | 3,9 | 4,7 | 6,1 | 6,9 | 3,5 |
| Y | 9,0 | 6,0 | 8,9 | 9,0 | 7,1 | 3,2 | 6,5 | 9,1 | 14,6 | 11,9 | 9,2 | 8,8 | 12,0 | 12,5 | 5,7 |
Постройте уравнение линейной регрессии прироста заработной платы от производительности труда и уровня инфляции. Проверьте качество построенного уравнения регрессии с надежностью 0,95. Проведите проверку наличия в модели автокорреляции на уровне значимости 0,05.
Решение. Подготовим данные для вставки из MS Excel (как транспонировать таблицу для сервиса см. Задание №2) .
Рисунок 1 – Ввод исходных данных (первый столбец Y, остальные Xi).
Включаем в отчет: Проверка общего качества уравнения множественной регрессии (F-статистика. Критерий Фишера, Проверка на наличие автокорреляции),
Рисунок 2 – Настройка отчета
После нажатия на кнопку Дале получаем готовое решение.
Уравнение регрессии (оценка уравнения регрессии):
Y = 0.2706 0.5257X1 1.4798X2
Скачать.
Качество построенного уравнения регрессии проверяется с помощью критерия Фишера (п. 6 отчета).
Пример №3.
В таблице представлены данные о ВВП, объемах потребления и инвестициях некоторых стран.
| ВВП | 16331,97 | 16763,35 | 17492,22 | 18473,83 | 19187,64 | 20066,25 | 21281,78 | 22326,86 | 23125,90 |
| Потребление в текущих ценах | 771,92 | 814,28 | 735,60 | 788,54 | 853,62 | 900,39 | 999,55 | 1076,37 | 1117,51 |
| Инвестиции в текущих ценах | 176,64 | 173,15 | 151,96 | 171,62 | 192,26 | 198,71 | 227,17 | 259,07 | 259,85 |
По представленным данным средствами Microsoft Excel определить:
- Средние значения величин;
- Дисперсии величин;
- Среднеквадратические отклонения величин;
- Ковариацию ВВП и потребления, ковариацию ВВП и инвестиций;
- Коэффициент корреляции ВВП и потребления, ковариацию ВВП и инвестиций;
- Коэффициент частной корреляции ВВП и потребления, коэффициент частной корреляции ВВП и инвестиций;
- Построить уравнение регрессии для зависимости ВВП от потребления. Определить коэффициент детерминации и сделать вывод о качестве полученного уравнения регрессии. С помощью t-теста проверить гипотезу H0: β = 0 для пятипроцентного уровня значимости и сделать вывод о значимости полученного коэффициента. Построить девяностопятипроцентный доверительный интервал для коэффициента регрессии b. С помощью F-теста проверить полученное уравнение регрессии на значимость. Провести t-тест для коэффициента корреляции.
- Построить уравнение множественной регрессии для зависимости ВВП от потребления и инвестиций. Определить коэффициент детерминации и сделать вывод о качестве полученного уравнения регрессии. С помощью t-теста проверить гипотезы H0: β1 = 0, H0: β2 = 0 для пятипроцентного уровня значимости и сделать вывод о значимости полученных коэффициентов. Построить девяностопятипроцентный доверительный интервал для коэффициентов регрессии b1, b2. С помощью F-теста проверить полученное уравнение регрессии на значимость. Провести t-тест для коэффициента корреляции.
Решение:
Для проверки полученных расчетов используем инструменты Microsoft Excel «Анализ данных» (см. пример).
Пример №4. На основе данных, приведенных в Приложении и соответствующих Вашему варианту (таблица 2), требуется:
- Построить уравнение множественной регрессии. При этом признак-результат и один из факторов остаются теми же, что и в первом задании. Выберите дополнительно еще один фактор из приложения 1 (границы наблюдения должны совпадать с границами наблюдения признака-результата, соответствующего Вашему варианту). При выборе фактора нужно руководствоваться его экономическим содержанием или другими подходами. Пояснить смысл параметров уравнения.
- Рассчитать частные коэффициенты эластичности. Сделать вывод.
- Определить стандартизованные коэффициенты регрессии (b-коэффициенты). Сделать вывод.
- Определить парные и частные коэффициенты корреляции, а также множественный коэффициент корреляции; сделать выводы.
- Оценить значимость параметров уравнения регрессии с помощью t-критерия Стьюдента, а также значимость уравнения регрессии в целом с помощью общего F-критерия Фишера. Предложить окончательную модель (уравнение регрессии). Сделать выводы.
Решение. Определим вектор оценок коэффициентов регрессии. Согласно методу наименьших квадратов, вектор получается из выражения:
s = (XTX)-1XTY
Матрица X
| 1 | 3.9 | 10 |
| 1 | 3.9 | 14 |
| 1 | 3.7 | 15 |
| 1 | 4 | 16 |
| 1 | 3.8 | 17 |
| 1 | 4.8 | 19 |
| 1 | 5.4 | 19 |
| 1 | 4.4 | 20 |
| 1 | 5.3 | 20 |
| 1 | 6.8 | 20 |
| 1 | 6 | 21 |
| 1 | 6.4 | 22 |
| 1 | 6.8 | 22 |
| 1 | 7.2 | 25 |
| 1 | 8 | 28 |
| 1 | 8.2 | 29 |
| 1 | 8.1 | 30 |
| 1 | 8.5 | 31 |
| 1 | 9.6 | 32 |
| 1 | 9 | 36 |
Матрица Y
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 7 |
| 8 |
| 8 |
| 8 |
| 10 |
| 9 |
| 11 |
| 9 |
| 11 |
| 12 |
| 12 |
| 12 |
| 12 |
| 14 |
| 14 |
Матрица XT
Умножаем матрицы, (XTX)
Умножаем матрицы, (XTY)
Находим определитель det(XTX)T = 139940.08
Находим обратную матрицу (XTX)-1Уравнение регрессии
Y = 1.8353 0.9459X 1 0.0856X 2
Для несмещенной оценки дисперсии проделаем следующие вычисления:
Несмещенная ошибка e = Y — X*s
| 0.62 |
| 0.28 |
| 0.38 |
| 0.01 |
| 0.11 |
| -1 |
| -0.57 |
| 0.29 |
| -0.56 |
| 0.02 |
| -0.31 |
| 1.23 |
| -1.15 |
| 0.21 |
| 0.2 |
| -0.07 |
| -0.07 |
| -0.53 |
| 0.34 |
| 0.57 |
se2 = (Y — X*s)T(Y — X*s)
Несмещенная оценка дисперсии равна
Оценка среднеквадратичного отклонения равна
Найдем оценку ковариационной матрицы вектора k = σ*(XTX)-1
| k(x) = 0.36 |
| = |
|
Дисперсии параметров модели определяются соотношением S 2i = Kii, т.е. это элементы, лежащие на главной диагонали
С целью расширения возможностей содержательного анализа модели регрессии используются частные коэффициенты эластичности, которые определяются по формуле
Тесноту совместного влияния факторов на результат оценивает индекс множественной корреляции (от 0 до 1)
Связь между признаком Y факторами X сильная
Частные коэффициенты (или индексы) корреляции, измеряющие влияние на у фактора хi при неизменном уровне других факторов определяются по стандартной формуле линейного коэффициента корреляции — последовательно берутся пары yx1,yx2,… , x1x2, x1x3.. и так далее и для каждой пары находится коэффициент корреляции
Коэффициент детерминации
R 2= 0.97 2 = 0.95, т.е. в 95% случаев изменения х приводят к изменению y. Другими словами — точность подбора уравнения регрессии — высокая
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл: Tтабл (n-m-1;a) = (17;0.05) = 1.74
Поскольку Tнабл < Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — не значим
Проверка гипотез относительно коэффициентов уравнения регрессии
1) t-статистика
Tтабл (n-m-1;α/2) = (17;0.025) = 2.11

Находим стандартную ошибку коэффициента регрессии b0:


Статистическая значимость коэффициента регрессии b0 подтверждается.
Находим стандартную ошибку коэффициента регрессии b1:


Статистическая значимость коэффициента регрессии b1 подтверждается.
Находим стандартную ошибку коэффициента регрессии b2:

Статистическая значимость коэффициента регрессии b2 не подтверждается.
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(bi — ti Sbi; bi ti Sbi)
b0: (1.84 — 2.11 • 0.47 ; 1.84 2.11 • 0.47) = (0.84;2.83)
b1: (0.95 — 2.11 • 0.21 ; 0.95 2.11 • 0.21) = (0.5;1.39)
b2: (0.0856 — 2.11 • 0.0605 ; 0.0856 2.11 • 0.0605) = (-0.042;0.21)
2) F-статистика. Критерий Фишера
Fkp = 3.2
Поскольку F > Fkp, то коэффициент детерминации статистически значим и уравнение регрессии статистически надежно
1) Рассчитайте корреляцию между, как минимум, тремя экономическими показателями из статистических данных по выборке не менее 15 наблюдений (из Интернета, печатных источников или Вашего предприятия). Интерпретируйте полученные данные.
2) Осуществите выбор зависимой (объясняемой) и объясняющей переменной для построения парной регрессионной модели. Дайте графическое изображение регрессионной зависимости. Определите теоретическое уравнение парной регрессии. Оцените адекватность построенной модели (интерпретируйте R-квадрат, показатели t-статистики, F-статистики).
3) Постройте регрессионную модель с 2-мя объясняющими переменными (множественная регрессия). Определите теоретическое уравнение множественной регрессии. Оцените адекватность построенной модели. Сравните адекватность модели с парной регрессией.
4) Проверьте любую из построенных моделей (парной или множественной регрессии) на отсутствие автокорреляции.
Рекомендации к решению контрольной работы.
Статистические данные по экономике можно получить на странице Россия в цифрах.
После определения зависимой и объясняющих переменных можно воспользоваться сервисом Множественная регрессия. Регрессионную модель с 2-мя объясняющими переменными можно построить используя матричный метод нахождения параметров уравнения регрессии или метод Крамера для нахождения параметров уравнения регрессии.
Пример №3. Исследуется зависимость размера дивидендов y акций группы компаний от доходности акций x1, дохода компании x2 и объема инвестиций в расширение и модернизацию производства x3. Исходные данные представлены выборкой объема n=50.
Тема I. Парная линейная регрессия
Постройте парные линейные регрессии — зависимости признака y от факторов x1, x2, x3 взятых по отдельности. Для каждой объясняющей переменной:
- Постройте диаграмму рассеяния (поле корреляции). При построении выберите тип диаграммы «Точечная» (без отрезков, соединяющих точки).
- Вычислите коэффициенты уравнения выборочной парной линейной регрессии (для вычисления коэффициентов регрессии воспользуйтесь встроенной функцией ЛИНЕЙН (функция находится в категории «Статистические») или надстройкой Пакет Анализа), коэффициент детерминации, коэффициент корреляции (функция КОРЕЛЛ), среднюю ошибку аппроксимации
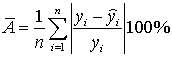 .
. - Запишите полученное уравнение выборочной регрессии. Дайте интерпретацию найденным в предыдущем пункте значениям.
- Постройте на поле корреляции прямую линию выборочной регрессии по точкам
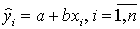 .
. - Постройте диаграмму остатков.
- Проверьте статистическую значимость коэффициентов регрессии по критерию Стьюдента (табличное значение определите с помощью функции СТЬЮДРАСПОБР) и всего уравнения в целом по критерию Фишера (табличное значение Fтабл определите с помощью функции FРАСПОБР).
- Постройте доверительные интервалы для коэффициентов регрессии. Дайте им интерпретацию.
- Постройте прогноз для значения фактора, на 50% превышающего его среднее значение.
- Постройте доверительный интервал прогноза. Дайте ему экономическую интерпретацию.
- Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемого фактора на показатель.
Создать шаблон решения онлайн
Тема II. Множественная линейная регрессия
1. Постройте выборочную множественную линейную регрессию показателя на все указанные факторы. Запишите полученное уравнение, дайте ему экономическую интерпретацию.
2. Определите коэффициент детерминации, дайте ему интерпретацию. Вычислите среднюю абсолютную ошибку аппроксимации и дайте ей интерпретацию.
3. Проверьте статистическую значимость каждого из коэффициентов и всего уравнения в целом.
4. Постройте диаграмму остатков.
5. Постройте доверительные интервалы коэффициентов. Для статистически значимых коэффициентов дайте интерпретации доверительных интервалов.
6. Постройте точечный прогноз значения показателя yпри значениях факторов, на 50% превышающих их средние значения.
7. Постройте доверительный интервал прогноза, дайте ему экономическую интерпретацию.
8. Постройте матрицу коэффициентов выборочной корреляции между показателем и факторами. Сделайте вывод о наличии проблемы мультиколлинеарности.
9. Оцените полученные результаты — сделайте выводы о качестве построенной модели, влиянии рассматриваемых факторов на показатель.
Анализ отзывов imdb к фильмам
Будем решать задачу бинарной классификации отзывов IMDB к фильмам. Имеется обучающая выборка с размеченными отзывами, по 12500 отзывов известно, что они хорошие, еще про 12500 – что они плохие. Здесь уже не так просто сразу приступить к машинному обучению, потому что готовой матрицы
Пример плохого отзыва:
‘Words can’t describe how bad this movie is. I can’t explain it by writing only. You have too see it for yourself to get at grip of how horrible a movie really can be. Not that I recommend you to do that. There are so many clichxc3xa9s, mistakes (and all other negative things you can imagine) here that will just make you cry. To start with the technical first, there are a LOT of mistakes regarding the airplane. I won’t list them here, but just mention the coloring of the plane. They didn’t even manage to show an airliner in the colors of a fictional airline, but instead used a 747 painted in the original Boeing livery. Very bad. The plot is stupid and has been done many times before, only much, much better. There are so many ridiculous moments here that i lost count of it really early. Also, I was on the bad guys’ side all the time in the movie, because the good guys were so stupid. «Executive Decision» should without a doubt be you’re choice over this one, even the «Turbulence»-movies are better. In fact, every other movie in the world is better than this one.’
Пример хорошего отзыва:
‘Everyone plays their part pretty well in this «little nice movie». Belushi gets the chance to live part of his life differently, but ends up realizing that what he had was going to be just as good or maybe even better. The movie shows us that we ought to take advantage of the opportunities we have, not the ones we do not or cannot have. If U can get this movie on video for around $10, itxc2xb4d be an investment!’
Составим словарь всех слов с помощью CountVectorizer. Всего в выборке 74849 уникальных слов. Если посмотреть на примеры полученных «слов» (лучше их называть токенами), то можно увидеть, что многие важные этапы обработки текста мы тут пропустили (автоматическая обработка текстов – это могло бы быть темой отдельной серии статей).
cv = CountVectorizer()
cv.fit(text_train)
print(len(cv.vocabulary_)) #74849print(cv.get_feature_names()[:50])
print(cv.get_feature_names()[50000:50050])[’00’, ‘000’, ‘0000000000001’, ‘00001’, ‘00015’, ‘000s’, ‘001’, ‘003830’, ‘006’, ‘007’, ‘0079’, ‘0080’, ‘0083’, ‘0093638’, ’00am’, ’00pm’, ’00s’, ’01’, ’01pm’, ’02’, ‘020410’, ‘029’, ’03’, ’04’, ‘041’, ’05’, ‘050’, ’06’, ’06th’, ’07’, ’08’, ‘087’, ‘089’, ’08th’, ’09’, ‘0f’, ‘0ne’, ‘0r’, ‘0s’, ’10’, ‘100’, ‘1000’, ‘1000000’, ‘10000000000000’, ‘1000lb’, ‘1000s’, ‘1001’, ‘100b’, ‘100k’, ‘100m’]
[‘pincher’, ‘pinchers’, ‘pinches’, ‘pinching’, ‘pinchot’, ‘pinciotti’, ‘pine’, ‘pineal’, ‘pineapple’, ‘pineapples’, ‘pines’, ‘pinet’, ‘pinetrees’, ‘pineyro’, ‘pinfall’, ‘pinfold’, ‘ping’, ‘pingo’, ‘pinhead’, ‘pinheads’, ‘pinho’, ‘pining’, ‘pinjar’, ‘pink’, ‘pinkerton’, ‘pinkett’, ‘pinkie’, ‘pinkins’, ‘pinkish’, ‘pinko’, ‘pinks’, ‘pinku’, ‘pinkus’, ‘pinky’, ‘pinnacle’, ‘pinnacles’, ‘pinned’, ‘pinning’, ‘pinnings’, ‘pinnochio’, ‘pinnocioesque’, ‘pino’, ‘pinocchio’, ‘pinochet’, ‘pinochets’, ‘pinoy’, ‘pinpoint’, ‘pinpoints’, ‘pins’, ‘pinsent’]
Закодируем предложения из текстов обучающей выборки индексами входящих слов. Используем разреженный формат. Преобразуем так же тестовую выборку.
X_train = cv.transform(text_train)
X_test = cv.transform(text_test)Обучим логистическую регрессию и посмотрим на доли правильных ответов на обучающей и тестовой выборках. Получается, на тестовой выборке мы правильно угадываем тональность примерно 86.7% отзывов.
Коэффициенты модели можно красиво отобразить.
def visualize_coefficients(classifier, feature_names, n_top_features=25):
# get coefficients with large absolute values
coef = classifier.coef_.ravel()
positive_coefficients = np.argsort(coef)[-n_top_features:]
negative_coefficients = np.argsort(coef)[:n_top_features]
interesting_coefficients = np.hstack([negative_coefficients, positive_coefficients])
# plot them
plt.figure(figsize=(15, 5))
colors = ["red" if c < 0 else "blue" for c in coef[interesting_coefficients]]
plt.bar(np.arange(2 * n_top_features), coef[interesting_coefficients], color=colors)
feature_names = np.array(feature_names)
plt.xticks(np.arange(1, 1 2 * n_top_features), feature_names[interesting_coefficients], rotation=60, ha="right");def plot_grid_scores(grid, param_name):
plt.plot(grid.param_grid[param_name], grid.cv_results_['mean_train_score'],
color='green', label='train')
plt.plot(grid.param_grid[param_name], grid.cv_results_['mean_test_score'],
color='red', label='test')
plt.legend();visualize_coefficients(logit, cv.get_feature_names())Подберем коэффициент регуляризации для логистической регрессии. Используем sklearn.pipeline, поскольку CountVectorizer правильно применять только на тех данных, на которых в текущий момент обучается модель (чтоб не «подсматривать» в тестовую выборку и не считать по ней частоты вхождения слов).
from sklearn.pipeline import make_pipeline
text_pipe_logit = make_pipeline(CountVectorizer(),
LogisticRegression(n_jobs=-1, random_state=7))
text_pipe_logit.fit(text_train, y_train)
print(text_pipe_logit.score(text_test, y_test))
from sklearn.model_selection import GridSearchCV
param_grid_logit = {'logisticregression__C': np.logspace(-5, 0, 6)}
grid_logit = GridSearchCV(text_pipe_logit, param_grid_logit, cv=3, n_jobs=-1)
grid_logit.fit(text_train, y_train)
grid_logit.best_params_, grid_logit.best_score_
plot_grid_scores(grid_logit, 'logisticregression__C')
grid_logit.score(text_test, y_test)Теперь то же самое, но со случайным лесом. Видим, что с логистической регрессией мы достигаем большей доли правильных ответов меньшими усилиями. Лес работает дольше, на отложенной выборке 85.5% правильных ответов.

